最近有很多研究提到,人工智能和自动化为主的技术进步,可能让女性就业受到比男性更大的冲击。
不过更进一步查看的话,所有这些文章会将深层原因归结于,女性更少的从事科学、技术、工程和数学 (STEM) 方向的学习;说大白话,就是女性没有学会编程,不懂电脑技术。
根据伦敦智库 IPPR 的研究,在自动化风险较高的行业中,近三分之二(64%)的英国工人是女性。这是因为众多女性从事的都是零售和行政工作,而这可以通过机器来完成。
IPPR 说:“总的来说,1/10 的女工面临着被机器人替代的高风险。相比之下,只有 4% 的男性工人有同类风险。” [1]
《金融时报》的文章指出,问题出在人们年轻的时候。高校 STEM 专业的学生约 65% 是男性。如果女性年轻时没有机会获得 STEM 相关学位,也就困于家务劳动和带孩子,而没有时间接受再培训。
文章说,新兴经济体许多女性面临更大的困难,因为她们当中有很多人从事仅能维持生计的农业,几乎没有受过教育,也没有什么可转移的技能。[2]
那么,为什么不直接说不会编程技能,或缺少编程思维的人更难找到工作呢?男人就没有这样对程序或基础科学一窍不通的吗?
我对这个问题如此敏感,一个原因是我本人(男)就是与 STEM 无缘的典型案例。
从小就喜欢计算机,却终究没学会编程
在我上高中之初,有一次机会选择文理科分班,这也是中国特色的教育方法。因为我在的高中比较强的是理科,我就选了理科,可是两学期下来,数学只能考 30 多分,物理、化学、生物全面亮红灯。
我对理科知识的唯一回忆,可能是刚上化学课的时候,问老师“石蕊(试纸)的化学式是什么”。没有答案,我只记住自己问了这个问题。
所以,我不得不由高一时的理科班转到文科班,不然的话根本没办法正常的考试。在文科班,我高考的分数也相对好一点,只是因为更多死记硬背的部分,更适合那个时候的我。
我深知考核标准的不同,会导致学生高考分数和社会评价的巨大差异。
有人说,农村孩子吃亏就在于高考不考种地、爬树、捉蟋蟀。都不用这么麻烦,其实文理分班已经能区分很大一部分同学的未来路径——但对某方向本来就很感兴趣,自己知道想要什么的同学除外。
我也知道自己有理科,也就是 STEM 学科方面的弱点。所以,即使我还没上学就用上了电脑,也把未来理想跟计算机捆绑在一起,却不能如愿以偿的从事程序员的工作;最后长大了,也不能由此转岗去做薪水更高,更稳定,前景也更好的编程行业,只能徘徊在电脑行业的边缘。
这一直是我心中的一个结。工作这么多年,我一直想要有机会去尝试从零开始自学编程,甚至给小朋友做启蒙的那些书我也看过,看完都一头雾水。
现在在三四线小城市,也经常出现人工智能和编程培训班的门脸,看了之后,除了更引起我被时代抛弃的焦虑之外,没有其他作用。
我作为科技记者和撰稿人,在掌握新科技趋势方面,属于起了大早,赶了晚集。
我们这些人应该处于整个科技食物链的比较靠下游的位置,最早知道了这些新闻和趋势,但除了写些文章或采访之外,几乎没有其他的方式可以妥善利用。结果,到了自己的工作受威胁的时候,宁可去卖保险。
这更多的是属于个人能力、兴趣偏好的问题,这根本就不是男女差异。
社会上没有一人一朵的“小红花”
我知道,如果我不能及时转到文科班的话,如果全校所有的同学都在理科班,甚至根本就没有文科,没有非 STEM 学科,那么我可能只是一个天资更加平庸的,成绩更差的理科生。在单一维度的评价体系里,我会比现在惨的多。
所以我说不上由理转文这件事,对我的人生是好是坏。从结果上看,我生存在社会尚且可以公平对待 STEM 和非 STEM 学科的时代,还是一件好事。
但是这其实更让我深刻领会到,未来继续保持这种评价体系和工作类型的多样化,对于我们这个社会的意义。
社会全面偏向 STEM 意味着我们的教育方针要做 180 度的大转弯,也不会存在什么“因材施教”的空间,这个问题是如此的严重,现在业界可能还没有充分的意识到问题的严重性。
分析人士只是笼统的说,人工智能虽然取消了很多岗位,但还可以创造更多岗位。想想工业革命!那些手工业者一开始破坏机器,搞卢德运动,但最后工人阶级还是站起来了。
不妨想想幼儿园和小学课堂里的“小红花”。用宽松的,素质教育的方法,老师就会说,班上每一个孩子都有闪光点,即使学习成绩不好,也有其他的评判标准。
如果出于孩子心理健康的考虑,给每个孩子单独设立一个评价体系的话,那么所有人都有小红花,最笨最没人缘的孩子也可以是“系鞋带最整齐的孩子”这样。这在学校里当然是成立的,走入现实可就不适用了。
本来,文史类学科和相关工作,以及程序化,缺乏创造力的工作,意味着“系鞋带最整齐的孩子”也有社会上对应的位置。
但如果说 AI 和自动化将替代的岗位是差不多全部非 STEM 行业,那就意味着全社会至少有一半曾经能够稳定就业的人,一瞬间不再适合在地球上生存。
原来能够给他们稳定收入和正面评价的行业,现在却露出冰冷的面孔。他们原来曾经学会的那些适应社会的习惯和能力,将会不再被人提起,连被评为非物质文化遗产的机会都没有。
培训和救济,似乎都很困难
前述智库给出的意见一般都是与福利、补贴和再教育相关。比如,IPPR 报告作者建议政府引入新的法律,给女性分配工作,开展高技能工作培训,提高最低工资标准等。
FT 的文章同样建议企业和社会推出举措,鼓励女孩学习 STEM 学科,发展编程技能。“不是每个人都需要成为一名程序员,但好的工作将越来越意味着与技术打交道。”
然而,这些文章所指出的理想状态,假设了女性(或其它 STEM 门外汉)只要经过培训,就都能达到一定标准。而不论男女,总有缺乏这方面天赋的人存在——比如我自己。
即使对他们进行失业的相关培训,也将会是困难重重的,因为如果他们真的掌握逻辑思维的能力,掌握学习数学的好方法,他们不是早就去做了吗?甚至他们连去参加培训的完整时间都不具备。
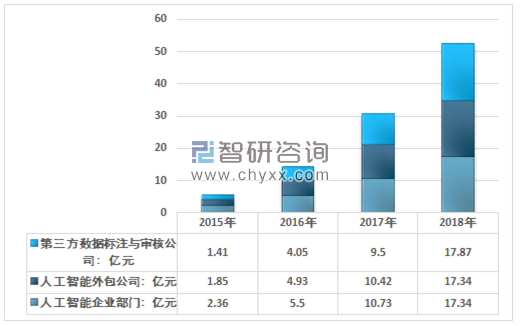
有人说,重复劳动类的劳动力,如果不会 STEM,可以做数据标注工人嘛。但是这样的标注,也是建立在个人隐私以及数据集可以被随意使用的草莽年代,建立在所谓“用隐私换便利”的时候。
受到社会制约的 AI 企业,将更倾向于用小的数据集,用压缩算法,最终达到能在用户个体的终端上,离线完成 AI 运算。当数据使用量减少的时候,数据标记工人只是会更快的迎来下一次失业。
我们再说说救济。现在,国家规定对公司招募残疾人、特定少数民族、退伍军人等执行补贴,这是在直接聘用他们会削弱企业市场竞争力的前提下,采取的平衡手段。
将来,这个巨大的救济包袱还会更重,因为以前能够自食其力的流水线组装工人、收银员、话务员等岗位都要归入救济队伍,他们本来应该是供养养老金的有生力量。福利的池水被加速抽干,每一个人分摊到的福利金额都会下降。
社会在考虑自动化新技术与就业的连带关系的时候,不能偷懒的只算工作总量和总失业率,因为这不是冷冰冰的数字,而是一个个具体的人,以及他们背后的家庭。
受影响的人当中,有多少人或者因为信息不对称,自己都没有察觉到,或者想到了,也因为没有天赋,没有兴趣或者没有财力精力,而只能默默的滑落下去。
我理解,一些研究者先假设不会 STEM 的都是女性,毕竟“女生学文科的多”,然后再跟性别话题挂钩,来引起人们注意。这是一种非常讨巧的尝试,可以利用现在风头正劲的女权思潮,利用她们强大的舆论动员力,来实现对自动化社会议题的关注。
但这实际上会模糊问题的焦点,并且使得跟他们所说的“女性”实质上具有同等问题的男人,更得不到关注,沦落为无人问津的“夹心层”。
结论
一个更自动化的社会,会显著的减少对一般人类劳动力的需求。在人类各种能力中,偏向创造力、想象力、沟通交流能力,以及控制机器的能力的一面会被更突出强调。
可惜的是,人类固有的缺陷——也可能是优势——就是,创意方面最强大的能力,往往只集中于极少数天赋异禀的英才手中。相比之下,一旦某个机器学会一个能力,它的任意一个复制品,都会一瞬间具备同样的能力。
也就是说,至少在教育方面,想要让人们往找到工作的方向走,依靠非标准化的非 STEM (“文科”)培训很难,而 STEM(“理科”)方向则较为容易。
这将不可挽回地导向全社会只重视 STEM 的单一评价标准,更多人将被判为不合格,没有能力赚到维持生活的钱。
要么继续思考怎么培训他们,要么就改变分配方式,比如给全民派钱什么的——这样的思考和讨论,已经到了非进行不可的时候。